在大数据时代,处理海量数据已成为企业运营与决策的核心需求。尤其是在互联网技术领域,无论是用户行为分析、日志处理,还是推荐系统优化,都需要对TB甚至PB级别的数据进行高效、准确的排序。Hadoop作为分布式计算框架的基石,为大规模数据的全局排序提供了强大的技术支持。
一、Hadoop排序的核心机制
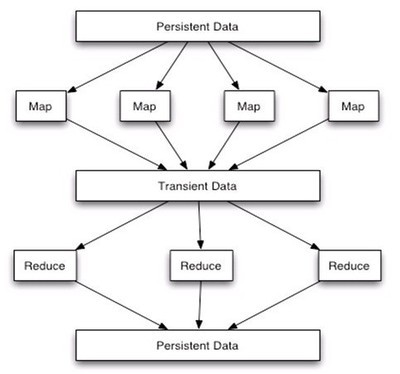
Hadoop的MapReduce编程模型天然支持排序。在Shuffle阶段,Map任务输出的中间结果会按照Key进行分区和排序,然后发送给Reduce任务。Reduce任务在接收数据时,也会对来自不同Map任务的相同Key的数据进行归并排序。这种机制使得在单个Reduce任务中,数据是全局有序的。
要实现真正意义上的全局排序(即所有数据按照一个全局顺序排列),通常需要一个Reduce任务。当数据量极大时,单Reduce任务会成为性能瓶颈。因此,实际应用中常采用“抽样-范围分区”的策略:
- 抽样阶段:运行一个抽样作业,从数据集中抽取少量Key样本。
- 生成分区文件:对样本进行排序,并根据样本的分布情况,计算出一个分区边界列表,确保每个分区包含大致相等的数据量。
- 全局排序作业:在正式的排序作业中,使用
TotalOrderPartitioner,并加载上一步生成的分区文件。这样,Map任务输出的数据会根据Key所属的范围被分发到不同的Reduce任务,每个Reduce任务处理一个范围的数据,并在内部进行排序。所有Reduce任务的输出按分区顺序拼接起来,就是全局有序的结果。
二、关键技术实现与优化
1. 自定义Key与Comparator
为了实现复杂排序逻辑(如二次排序),需要自定义WritableComparable的Key类,并实现compareTo方法。可能需要为Map端排序、Reduce端分组和Reduce端排序分别设置不同的Comparator。
2. 使用Combiner减少数据传输
在Map端使用Combiner进行本地聚合,可以显著减少Shuffle阶段需要传输的数据量,提升整体性能。但需注意,Combiner的操作必须是幂等的,且不影响最终结果。
3. 内存与磁盘优化
调整io.sort.mb(Map端排序缓冲区大小)、io.sort.factor(归并因子)等参数,可以在内存使用和磁盘I/O之间找到最佳平衡点,防止作业因内存溢出而失败。
4. 并行度调优
合理设置Reduce任务的数量至关重要。数量太少会导致单个任务负载过重,太多则会增加任务启动和调度的开销。通常,Reduce任务数可设置为集群中可用Reduce槽位的0.95到1.75倍。
三、在互联网技术与电脑动画设计中的应用
互联网技术领域
- 用户画像与行为分析:对数十亿用户的点击流、购买记录按时间或权重排序,进行趋势分析和用户分群。
- 搜索引擎索引构建:对全网爬取的海量网页数据,按PageRank、关键词相关性等指标进行排序,生成倒排索引。
- 广告点击率(CTR)预估:对海量的广告曝光、点击日志按用户、广告位等进行排序,用于模型训练和效果评估。
电脑动画设计领域
随着3D动画、特效渲染的数据量激增,Hadoop排序也能发挥作用:
- 渲染任务调度:对成千上万的渲染帧任务,根据复杂度、依赖关系、优先级进行全局排序,优化渲染农场的任务队列,提高整体渲染效率。
- 资产管理与版本控制:对庞大的模型、纹理、动画序列文件,按修改时间、文件大小或项目依赖进行排序,便于团队协作和资产管理。
- 动作捕捉数据处理:对连续的动作捕捉数据流(如MoCap数据),按时间戳进行全局排序和清洗,为后续的动画合成提供准备。
四、实践注意事项
- 数据倾斜问题:如果某个Key的数据量异常庞大,会导致对应的Reduce任务执行缓慢,成为“拖后腿”的任务。需要通过更好的抽样策略或自定义分区逻辑来缓解。
- 容错与监控:Hadoop作业运行时间可能很长,需关注作业进度、资源使用情况,并处理好可能的失败重试。
- 输出格式:排序后的输出通常选择顺序文件格式(SequenceFile),它能更好地支持大数据块和压缩,便于后续处理。
###
利用Hadoop进行大规模数据的全局排序,是一项将分布式计算理论付诸实践的关键技术。通过深入理解MapReduce的排序机制,并结合巧妙的抽样分区策略,我们能够高效地驾驭海量数据,为互联网服务和数字内容创作(如电脑动画设计)提供深度的数据洞察和强大的处理能力。随着计算框架的演进(如Spark在某些场景下提供了更优的排序性能),其核心思想——分而治之、抽样与范围分区——依然是处理超大规模数据排序的宝贵财富。